-
개요 : 리눅스 커맨드라인은 신입 개발자의 기본 소양. 알면 알수록 빠르고 편해진다.
- 리눅스는 수십년을 이어온 강력한 툴.
- 리눅스는 GUI 프로그램만으로는 조금 부족. 알수록 강력함.
- 개발 환경/ 소프트웨어 구동 환경으로 리눅스를 사용하는 곳이 많다.
- 클라우드 환경에 설치되는 가상 OS 의 비율은 리눅스 9 : 윈도우즈 1
- 사람은 GUI 프로그램을 사용할 수 있지만 소프트웨어는 GUI 프로그램을 사용할 수 없다. 시스템 프로그래밍, 커맨드 라인 툴을 이용해 시스템 정보를 처리해야 한다
-
텍스트 처리
- 옵션
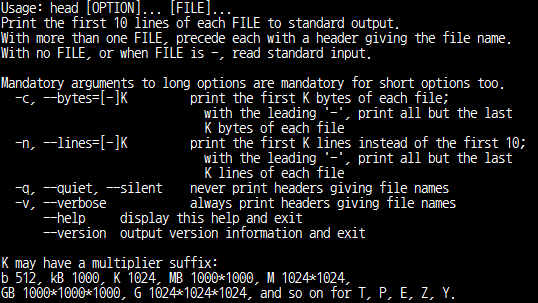
- -c, --bytes=[-]NUM : NUM byte만 출력, byte 입력시 K,M,G,T 입력가능
- -n, --lines=[-]NUM : NUM line만 출력
- NUM '-'입력시 문서의 마지막 NUM byte/line 을 제외하고 출력
- head -n -5 /etc/test.txt : test.txt파일의 마지막줄 5줄을 제외하고 출력하라
- head : 문서 내용의 앞부분을 출력하는 명령어. 기본적으로 10줄 출력.
- cat : 문서 내용의 처음부터 끝까지를 전부 출력하는 명령어.

- tail : 문서 내용의 뒷 부분 출력하는 명령어. 옵션이 없으면 기본적으로 마지막 10줄을 출력.
- 옵션
- -c, --bytes=[+]NUM : NUM byte만 출력, byte 입력시 K,M,G,T 입력가능
- -n, --lines=[+]NUM : NUM line만 출력
- NUM '+'입력시 문서의 마지막 NUM byte/line 에서 출력 시작
- -f, --follow[={name|descr}] 추가되는 내용 대기. 추가되는 내용은 append 하여 출력
- -F, 파일이 truncate 되는 경우 re-open하여 follow 함(로그 파일이 너무 커지는 것을 대비한 logrotate되는 파일에 유용)
- 모니터링이나 디버깅할때 자주 사용되는 명령어.

- wc : word count 명령어 문서의 워드/라인/캐릭터가 몇개나 있는지에 대해 세주는 명령어
- wc -l /etc/test.txt | awk '{ print $1 }'
- awk '{ print $1 }' 띄어쓰기를 기준으로 첫번째 토큰을 출력하라
- wc -l /etc/test.txt | cut -d ' ' -f 1
- cut -d ' ' -f 1 공백을 기준으로 토큰화해서 첫번째 토큰을 출력해라
- 옵션
- -l : 라인수만 출력
- 라인수가 중요한 이유는 자유롭게 메모장에 일기를 적는다하면 그 줄수는 중요히 않음. head와 tail에서 본 것처럼 한 줄에 하나의 설정이 들어가는 파일이 있을 수 있음. 라인이 3줄이면 설정값이 3개 있구나 하고 알 수 있음. 이런 경우가 빈번하기 때문에 라인의 갯수를 알게 되면 유용하게 사용할 수있다.
- 옵션없이 사용할 경우 라인/워드/byte count가 전부 출력된다.
- 두개 이상의 파일을 한꺼번에 출력하고 합계 정보 또한 출력할 수 있다.
- 필요한 라인수만 가져다가 쓰고 파일명은 제거하길 원할 경우 cut이나 awk 명령어 사용가능.

- nl : 파일 내용을 출력할때 라인넘버를 붙여서 함께 출력해주는 명령어
- nl [FILENAME]
- cat [FILENAME] | nl
- nl로 조회시 아무것도 기재되지 않은 라인에는 라인수가 카운트되지 않음. wc로 카운트시 전체 라인수와 차이가 생긴다. 이런 경우에 사용하는 것이 -ba옵션.
- 옵션
- -ba : 모든 라인에 대해 라인 넘버링. 공백인 줄도 같이 카운팅.
- -v N : 시작 라인 넘버를 N으로 지정
- -s : 라인 넘버 출력 후 출력할 separator 지정
- 문서 작성시 코드를 첨부해서 설명해야 할 경우 라인 넘버로 설명하는 것이 편리하다.

- sort : 정렬하여 출력
- -k, --key=KEYDEF : key에 의한 정렬 수행
- -t, --field-seperator : 필드 구분자(기본값은 공백 문자). 컬럼을 나뉘어 주는 것(마치 엑셀처럼)
- -f, --ignore-case : 대소문자 구분 없음
- -g, --general-numeric-sort
- -n, --numeric-sort : 숫자로 인식해서 정렬
- -r, --reverse : 기본적으로 오름차순이므로 내림차순 정렬 진행
- -u, --unique : 행과 행이 일치하는 경우 중복되는 줄을 제거해서 하나만 출력
- 콜론을 기준으로 행을 분리해서 세번쨰 컬럼을 키값으로 해서 정렬
- 파일 크기로 정렬.
- 위치지정
- 정렬기준
- 대부분 특정 컬럼을 지정하여 정렬하는 일이 많음.
- cat /etc/test.txt | sort -t: -k 3
- --debug 옵션을 추가하면 어느 기준으로 정렬을 한건지 조회할 수 있다.
- key값은 여러 개 설정할 수 있다.
- ls -al | sort -k 5 -n

- uniq : 중복된 내용 제거하고 출력
- 옵션
- -d, --repeated : 중복된 내용만 출력
- -u, --unique : 중복되지 않은 내용만 출력
- -i, --ignore-case : 대소문자 무시
- 연속적으로 중복된 내용만 제거해주므로 sort와 함께 사용한다
- sort [파일명] | uniq -i | nl

- cut : 컬럼 잘라내기. 문서의 내용에서 기준을 가지고 잘라내서 출력할 때 사용.
- 라인수와 파일명을 출력한 결과중에 첫번째 필드를 출력해라. 출력하는 구분자는 >로 사용
- 옵션
- -b, --bytes=LIST : byte 선택. range 설정 가능.
- -c, --characters=LIST : character 선택
- -f, --fields=LIST : 필드 컬럼 선택. 필드는 여러 개 선택이 가능하다.
- -d, --delimiter=DELIM: tab대신 사용할 구분자 지정. -d 옵션이 없으면 tab으로 반영
- --complement
- --output-delimiter=STRING
- wc /etc/test.txt -l | cut -d ' ' -f 1,5 --output-delimeter=">"

- tr : 어떤 내용을 변환(translate)한다. 변환되는 내용은 옵션에 따라 다르다.
- CHAR1-CHAR2 : char1부터 char2까지의 문제 세트(예 : 'a-z')
- [:alnum:] : 문자 + 숫자
- [:alpha:] : 문자
- [:blank:] : 공백
- [:space:] : 공백 + newline
- [:digit:] / [:xdigit:] : 10진수 숫자 / 16진수 숫자
- [:lower:] / [:upper:] : 소문자 / 대문자로 변환
- 현재 경로에서 /를 모두 지워서 출력
- 현재 경로에서 /자리에 %로 변환하겠다.
- 모든 소문자를 대문자로 변환.
- 기본 사용법 : tr [OPTION] … SET1 [SET2]
- 옵션
- -c, -C, --complement
- -d, --delete
- SET
- 특수한 캐릭터를 지울때 사용하는 경우 쓰일 수 있음.
- pwd | tr -d '/'
- pwd | tr '/' '%'
- pwd | tr [:lower:] [:upper:]
- 소스코드로 만들어야 하면 파일을 읽고 변환해서 내보내는 작업이 이뤄지므로 복잡해진다. 리눅스 단에서 처리하게 되면 tr를 사용한 커맨드 라인으로 간단하게 사용할 수 있다.
- sed : stream editor. 사용자가 조작할 수 있도록 도와주는 에디터.
- 한줄씩 읽으면서 처리하기 때문에 기본적으로 처리된 후 스트림을 받아 sed가 수행된다. 2~5줄은 두번씩 출력된다. 2~5만 출력되길 원한다면 -n 옵션을 추가해야 한다.
- 검색된 내용만 출력해라
- 검색되지 않은 내용만 출력해라
- root를 ROOT로 교체해서 출력
- 옵션
- {RANGE}p : range 내의 라인을 출력
- {RANGE}d : range 내의 라인을 삭제
- /SEARCHPATTERN/p : SEARCHPATTERN과 매치되는 라인을 출력
- /SEARCHPATTERN/d : SEARCHPATTERN과 매치되는 라인을 삭제
- s/REGEX/REPLACE/ : REGEX에 매치되는 부븐을 REPLACE로 교체(substitute). 치환
- head /etc/test.txt | sed '2,5p'
- head /etc/test.txt | sed -n '/sy/p'
- head /etc/test.txt | sed -n '/sy/d'
- head /etc/test.txt | sed -n 's/root/ROOT/'
- awk : 텍스트 처리 script language.
- -F : field seperator 지정
- $1, $2, $3, … : Nth field
- NR : number of records
- NF : number of fields
- FS : field separator(default 'white space')
- RS : record separator(default 'new line')
- OFS : output field separator
- ORS : output record separator
- /를 구분자로 필드를 구분해서 첫번째 필드를 출력
- /를 구분자로 sy일치하는 필드를 찾아 세번째 필드를 출력
- 레코드수와 세번째 필드를 출력
- syntax : awk options 'selection _criteria {action }' input-file
- 옵션
- 주요 내장 변수
- ls -al | awk '{ print $1 }'
- wc -l /etc/test.txt | awk -F/ '{ print $1 }'
- wc -l /etc/test.txt | awk -F/ '/sy/ { print $3 }'
- wc -l /etc/test.txt | awk -F/ '/sy/ { print NR $3 }'
- 복잡한 스크립트를 작성하게 되면 다양한 내장변수를 사용하게 된다.
-
검색
- find [OPTION] path EXPR
- 옵션
- -name : 이름으로 검색
- -regex : regex에 매치로 검색
- -empty : 빈 디렉토리 혹은 빈 파일 검색
- -size : 파일 사이즈로 검색(M, G로 표기 가능)
- -N : 이하
- +N : 이상
- -type : 파일 타입으로 검색
- d : directory
- p : named pipe
- f : regular file
- l : softlink
- s : socket
- -perm : 퍼미션으로 검색
- mode : 정확히 일치하는 파일
- +mode : 모든 flag가 포함된 파일
- /mode : 어떤 flag라도 포함된 파일
- -delete : 파일 삭제
- -ls : ls -dils 명령 수행. 파일 사이즈 등 여러가지 필드를 보여줌
- -print : 파일 이름을 출력(default)
- -printf : 파일 이름을 포맷에 맞게 출력
- -exec : 주어진 명령 수행
- -execdir : 해당 디렉토리로 이동하여 명령 실행
- -ok : 사용자에게 확인 후 exec. 파일을 찾아 실행하는게 맞는지 한 번 더 확인
- -okdir : 사용자에게 확인 후 실행 execdir.
- 조건
- 액션(유용하지만 잘못 사용하면 재앙이 될 수 있음)
- grep [OPTIONS] PATTERN [FILE…]
- 옵션
- -r : recursive. 디렉토리의 하위까지 반복하면서 탐색.
- -i : ignore case. 대소문자 무시
- -v : invert match. 패턴과 매치가 되지 않는 것들을 찾아준다.
- -q : quiet mode. 화면상 아무런 것도 출력하지 않는다. 검색 성공 시 성공값 리턴. (0이 성공. 1이 실패)
- grep stdio *.c
- grep ftok *.c | awk -F: '{ print $1 }' | sort -u
- ftok가 쓰여진 c파일을 찾는데 :을 구분자로처 첫번째 필드를 유니크로 정렬해서 보여줘라.
- grep "\<for\>" *.c
- 단어 단위로 패턴을 검색
- 자주 사용하는 옵션 : -s, --section=LIST, --section=LIST : 탐색할 섹션을 colon으로 구분하여 입력
- 파일 시스템 전체에 대해서 검색을 진행하는데 직접 검색하는 게 아니라 인덱싱을 이용한다. updatedb를 만들어두고 이 파일을 뒤져서 검색하는 것.
- 단, updatedb가 저장해놓은 DB파일 내에서 검색하므로 누락파일이 생길 수 있다.
- locate [OPTION] … PATTERN…
- 옵션
- -i, --ignore-case : 대소문자 구분없이 검색
- -l, --limit, -n limit : 출력결과를 LIMIT 만큼만 출력
- --regex : PATTERN을 regex로 해석
- 일반적인 파일은 검색이 안되고 실행파일만 가능하다.
- ls라는 쉘 파일을 수정해서 실행하고 싶은데 위치를 몰라 알고싶을 때 사용한다.
- PATH라는 환경변수를 따라가면서 해당 명령어가 어디있는지 depth를 내려가면서 검색한다.
- find : 파일의 이름이나 속성을 이용해 조건에 맞는 파일을 찾아 명령을 수행한다
- grep : 파일 내용 중 원하는 내용을 찾는다.
- apropos : 정확한 함수명이나 커맨드가 기억나지 않을 경우 man page 이름과 설명을 검색한다.
- locate : 파일의 위치를 찾아 보여준다
- which : 실행파일의 위치를 보여준다.
-
시스템 정보
- ps
- ps -elf(-aux)
- 현 시스템에서 수행중인 프로그램과 데몬 상태를 보여주는 명령어이다.
- top
- 시스템 자원(cpu, memory 등)의 사용현황을 보여준다.
- lsof
- list open files을 뜻하는 명령어이다.
- 수많은 유닉스 계열 운영 체제에서 열려있는 모든 파일과, 그 파일들을 열고 있는 프로세스들의 목록을 출력한다.
- netstat
- 현 시스템에서 사용되는 통신 서비스의 상태를 보여준다.
- 개인적으로 많이 사용하는 옵션은 -anpt 이다.
- sysctl
- sysctl은 버전 번호나 보안 설정 같은 시스템 커널의 속성들을 읽고 수정하는 명령어이다.
- ps
-
텍스트 편집
- vim
-
개발 도구
- diff
- patch
- cscope
- ctags
- strace
- gdb
- valgrind
이 내용은 리눅스 커맨드라인 툴 강의를 보고 정리하였습니다
https://www.inflearn.com/course/command-line#
'CS > OS' 카테고리의 다른 글
| [Linux] 자주 사용하는 명령어 정리1 (0) | 2019.09.28 |
|---|---|
| [Linux] RPM 과 YUM (0) | 2019.09.27 |
| [Linux] 생활코딩 리눅스 강좌 (3) (0) | 2019.09.23 |
| [Linux] 생활코딩 리눅스 강좌 (2) (0) | 2019.09.17 |
| [Linux] 생활코딩 리눅스 강좌 (1) (0) | 2019.09.16 |