[제약조건]
제약조건 조회

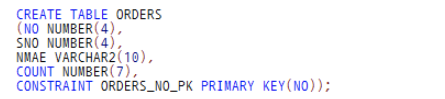
[PRIMARY KEY]
1. COLUMN LEVEL : 컬럼 생성시 제약조건 기재.

2. TABLE LEVEL : 컬럼 생성후 마지막으로 제약조건 기재.
좀 더 직관적으로 볼 수 있어서 테이블 레벨로 만드는 것을 더 선호함 (1보다 2선호)
[FOREIGN KEY]

▲CUSTOMER TABLE ▲ORDERS TABLE ▲CATALOG1 TABLE
1. 참조키 제약조건 ALTER를 통해 수정
- ORDERS 테이블의 ‘NO’열을 외래키로 가져옴

2. 참조키 제약조건 테이블 생성시 입력
- ORDERS 테이블의 ‘NO’열을 외래키로 가져옴

3. ORDERS 테이블에 NO 값이 없다면 참조무결성 위반으로 입력 불가능함
- 무결성 제약조건(KIM.CATALOG1_NO_FK)이 위배되었습니다- 부모 키가 없습니다
- 무결성 제약조건(KIM.CUSTOMER_NO_FK)이 위배되었습니다- 부모 키가 없습니다

[UNIQUE KEY]
1.제약조건 설정

2.중복값을 허용 하지 않고, NULL은 허용함

3.테이블 생성시 제약조건 설정

[CHECK 제약조건]
1. 하나의 컬럼에 두가지 이상의 제약조건이 들어가도 문제없음. (서로의 데이터 영역에 문제를 끼치지 않는다면 !

2. 60은 10~50 범위에서 벗어나므로 오류 발생
- ORA-02290: 체크 제약조건(KIM.ORDERS_SNO_CK)이 위배되었습니다

[NOT NULL]
1. 제약조건 설정

2. 비교를 위해 체크 제약조건 생성

3.설정 후 확인

4. NOT NULL은 체크 제약조건으로 들어가게 됨. 사용하는데 큰 차이는 없음 !
5. MODIFY를 사용해서도 작성 가능

[제약조건의 추가, 삭제 - ※수정은 없다]
1.PRIMARY KEY 삭제
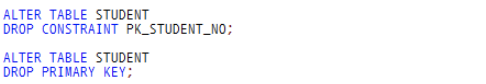
2.참조키로 사용되는 컬럼은 CASCADE로 한꺼번에 삭제 가능

3.삭제 전:

4.삭제 후

5. UNIQUE KEY 삭제

[제약조건 비활성화]
1. 당장 급하게 데이터를 넣은(제약조건 생략) 후, 중복데이터를 나중에 분류하는 작업을 해야할 때 사용
2. 비활성화 (삭제하는 것이 아니라 지금 당장 사용하지 않으므로 비활성화 시킴)

3. 상태 조회


4. 활성화 : 비활성화는 CASCADE로 한꺼번에 할 수 있지만 활성화는 그럴 수 없음. 일일이 작업 해줘야 함
[DATA DICTIONARY]
1 .내가 사용할 수 있는 딕셔너리 조회

2. USER_ ⊂ ALL_ ⊂ DBA_
3. USER_ : USER 소유의 OBJECT 정보 (자신소유의 정보)
4. ALL_ : USER에게 ACCESS가 허용된 OBJECT 정보 (OBJECT권한을 받았기 때문)
-> 내가 만들지 않았더라도 권한을 받았으면 접근가능
5. DBA_ : DBA 권한을 가진 USER 소유의 OBJECT 정보. 말그대로 DBA만 실행시킬 수 있음
6. V$ : SERVER의 성능에 관련된 정보

7. 시스템의 현재 상태에 관한 정보 조회 가능

[VIEW]
1. VIEW는 가상테이블. 보안을 위해 사용. 생성해놓은 뷰의 데이터만 조회가 가능하기 때문. 열제한, 행제한 가능-조건절 입력

2. VIEW 생성.- SIMPLE VIEW : 하나의 데이터에서 SELECT한 VIEW

3. VIEW 조회

4. 사용자의 VIEW 조회

5. 생성된 VIEW 에 추가로 조건문 사용 가능

6. INSERT, UPDATE, DELETE가 가능

7. INSERT 에러
NULL을 ("KIM"."PERSONNEL"."PNO") 안에 삽입할 수 없습니다
원래 테이블인 "PERSONNEL의 PRIMARY KEY( PNO)에는 NULL 값이 들어갈 수 없으므로 오류

8. VIEW 수정 (CREATE -> ALTER) : 없으면 만들고 있으면 수정: CREATE OR REPLACE


9. VIEW 삭제

10. COMPLEX VIEW(JOIN)
- INSERT, UPDATE, DELETE가 불가능하다.
- SELECT 만 가능하다.

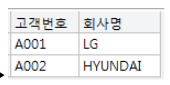
11. COMPLEX VIEW생성


▼정보VIEW는 COMPLEX VIEW이므로 삽입,수정,삭제 불가

12. WITH CHECK OPTION - 체크 제약조건이 존재하는 뷰

13. WITH READ ONLY - 읽기 전용 뷰

14. TOP-N
MS-SQL에서는 간편하게 사용가능
SELECT TOP 5 PNAME,STARTDATE FROM PERSONNEL ORDER BY STARTDATE DESC;
SELECT TOP 5 PERCENT PNAME,STARTDATE FROM PERSONNEL ORDER BY STARTDATE DESC;
15. ROWID

DB/TABLESPACE/TABLE/행에 대한 정보가 일렬번호로 나오는 것. 하나의 레코드에 대한 고유값
ROWID가 같으면 같은 데이터
[SYNONYM - 동의어]
1. SYNONYM 생성 권한 부여해줘야 가능

2. SYNONYM 생성
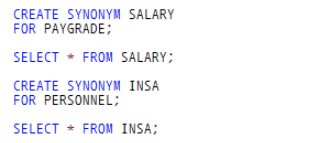
3. 공용 동의어

4. KIM에서 OBJECT권한 부여(사용자가 사용자에게 부여. KIM에서 해도 되고 관리자 계정에서 해도됨)

5. 공용 동의어 삭제
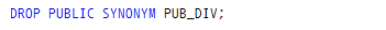
6. 동의어 삭제

[오라클_데이터베이스_인덱스 아키텍쳐]
1. 데이터베이스모델 = 논리적모델 + 물리적모델
2. BLOCK : SQL에서 데이터를 저장하고 처리하는데 사용되는 가장 기본적인 입출력 단위. 컴퓨터에서 가장 작은 데이터단위는 bit
- 총크기 각 블록당 8KB (8192byte의 저장공간. 1024byte * 8)
- 헤더 저장공간 96byte. (block의 종류, 여유공간정보, Object ID 저장)
- 실저장공간 : 8096byte. (1Mbyte = 1024Kbyte 128개의 block)
3. EXTENT : 공간할당의 기본단위이며. block들을 묶어놓은 논리적인 단위
- 연속된 8개의 block으로 구성 64kb. ( ms-sql에서는 이렇게 정해져있고. 오라클에서는 extent의 크기를 지정할 수 있음)
- 각 메가당 16개의 extent
- 1024kb/64kb = 16개
- page = block
4. 데이터 block 구조
- 형태 : block 헤더 / 데이터로우1/ 데이터로우2 / 여유공간
- 별도의 블록에 저장되는 text,ntext,image형의 데이터형태를 제외한 모든 데이터 로우를 저장
- text, ntext,image는 데이터의 크기가 너무 크기때문에 데이터페이지의 부담이 큼
- 요새는 데이터자체가 아니라 해당데이터가 저장된 주소를 저장.
- ▶ 하드디스크 스토리지의 주소를 저장해두고 DB는 가벼워지고 데이터는 관리가 잘되는 장점이 있음)
- block헤더영역에는 각 block의 전후관계에 대한 포인터를 가지고 있다.(linked list 형태 )
5. 데이터 block의 동작 원리
- 클러스터드 테이블(Clustered table) : ms - sql이 지향
- 인덱스 순서 = 물리적인 데이터 block 순서
- 테이블 하나만 적용가능. ▶ PRIMARY KEY와 인덱스가 둘다 존재할 경우 정렬하는 기준이 여러개가 되서 데이터 꼬일 수 있으므로 테이블 하나에만 적용이 가능한 것
- 데이터가 들어갈때마다 정렬
- 장점: 데이터를 select할때 빠름, 단점: insert, update, delete 할때 느림.
- A - B - C - D - E ….
- 넌클러스터드 테이블(Non-clustered table): 오라클이 지향.
- heap 힙
- 인덱스순서 <>물리적인 데이터 block 순서
- 데이터가 삽입되는 무작위 상태
- 테이블에 여러개 적용가능 (최고 249개)
- 장점: 데이터를insert, update, delete 할때 빠름, 단점: select할때 느림.
- B - C - A - E - F - G …..
[INDEX]
Index Search Methodology 인덱스 검색 방법론
Table Scan Methodology 테이블 검색 방법론
-인덱스 사용의 문제점
추가시간 : 검색시간 < 추가,수정,삭제시간
별도저장공간 : 데이터와는 별도 장소에 저장. 데이터 저장 크기의 5~20%
관리자의 수고 : 인덱스 재설정(Rebuild), 단편화
- Index의 자료구조
b-tree 구조 인덱스 : 나무를 거꾸로 뒤집어 놓은 형태 . Non-clustered Index. 물리적인 데이터 저장순서가 무작위로 들어감
cluster 인덱스
[Non- clustered index]
- RowId 생성 : 데이터파일, 데이터블록번호, 로우번호 (데이터오브젝트번호, 파일번호, block번호, row번호가 합쳐져서 RowId가 됨.)
인덱스 블록이 데이터블록보다 많은 양의 레코드들을 저장
인덱스들은 인덱스된 해당 컬럼과 약간의 오버헤드로 구성
- index를 통해 이뤄지는 select 프로세스
색인 컬럼의 키값을 정렬 . rowid 정렬됨
정렬된 인덱스 컬럼을 기준으로 데이터 블록을 만듦 ( rowid 기록)
leaf level이 완성되면 non leaf level을 만듦 ( rowid 기록안함)
- 단일 데이터 검색 point query
새로운 데이터 추가시 페이지가 분할되는 (인덱스페이지가 분할됨) 단편화 현상이 발생. 메모리 낭비가 심함.
심지어 단편화된 페이지에 데이터가 추가되지않음. 그래서 관리자가 블록을 합쳐주는 작업 정기적으로 필요.
[clustered index]
인덱스 페이지 자체가 정렬이 되어있으므로 많은 작업이 생략될 수 있음.
테이블에 반드시 인덱스가 있어야 함. 인덱스가 있으면 속도가 개선 됨.
'RDB > Oracle' 카테고리의 다른 글
| [오라클]DML 프로시저, 함수, 반복문, 예외처리,커서 (0) | 2019.01.21 |
|---|---|
| [오라클]인덱스, 시퀀스, PL/SQL-프로시저의 개념, 스크립트 (0) | 2019.01.18 |
| [오라클]DCL, OBJECT 권한, ROLE (0) | 2019.01.16 |
| [오라클]서브쿼리, 무결성, 트랜잭션, DDL, 정규화 (1) | 2019.01.16 |
| [오라클] 예제풀이 5 (0) | 2019.01.16 |